sorka
2024. 4. 23. 21:29
2024. 4. 23. 21:29
시스템 아키텍처
- 플링크는 상태가 있는 병렬 스트림을 처리할 수 있는 분산 시스템
- 분산시스템은 일반적으로 클러스터의 컴퓨팅 자원 관리, 프로세스 조율, 신뢰성과 고가용성을 갖춘 데이터 저장소 및 장애 복구와 같은 여러 어려운 문제 다뤄야 함
- 플링크는 핵심 기능인 분산 데이터 스트림 처리에만 집중하고 나머지 기능은 기존 클러스터 인프라와 서비스를 이용
- 아파치 메소스, YARN, 쿠버네티스와 같은 클러스터 자원관리자와 통합. 독립형(standalone)클러스터로도 설정해 실행 가능
- 신뢰성 있는 분산 저장소 제공하지 않지만 HDFS나 객체 저장소인 S3같은 파일 시스템 이용
- 고가용성에서 필요한 리더 선출(leader election) 기능은 아파치 주키퍼 사용
플링크 컴포넌트
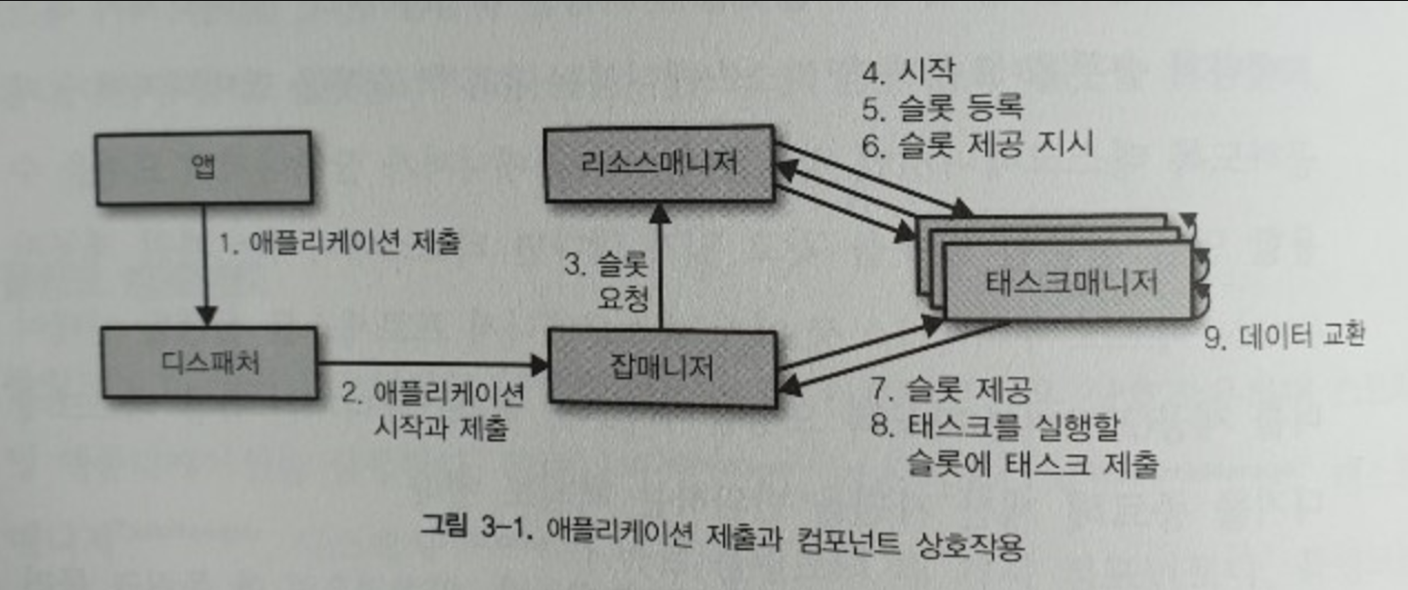
- 네 개의 컴포넌트로 구성 : 잡매니저(JobManager), 리소스매니저(ResourceManager), 태스크매니저(TaskManager), 디스패처(Dispatcher)
- 플링크는 자바와 스칼라로 구현됐기 때문에 모든 컴포넌트를 자바 가상머신(JVM)에서 실행 가능
- 잡매니저
- 애플리케이션의 실행을 제어하는 마스터 프로세스
- 애플리케이션은 잡그래프(JobGraph)라 부르는 논리 데이터플로우 그래프와 애플리케이션에 필요한 모든 클래스, 라이브러리, 기타 자원을 포함하는 JAR로 구성
- 잡매니저는 잡 그래프를 실행그래프(ExecutionGraph)라 부르는 물리 데이터플로우 그래프로 변환
- 리소스매니저에서 태스크 실행에 필요한 자원(태스크매니저 슬롯(slot))을 요청
- 애플리케이션을 실행할 수 있는 충분한 태스크 슬롯을 할당받으면 잡매니저는 작업을 처리할 태스크로 실행그래프 배포
- 애플리케이션 실행 중 체크포인트를 조율하고 중앙에서 제어해야 하는 모든 동작을 책임짐
- 리소스 매니저
- YARN, 메소스, 쿠버네티스, 독립형 클러스터와 같은 각 환경에서 자원을 관리할 수 있는 리소스매니저를 지원
- 플링크의 실행 단위인 태스크매니저 슬롯을 관리
- 잡매니저가 태스크매니저 슬롯을 요청하면 리소스매니저는 유휴(idle) 슬롯을 잡매니저에게 제공하도록 태스크매니저에 지시
- 잡매니저의 요청을 수용할 만큼 충분한 슬롯을 갖고 있지 않다면 자원 제공자(YARN, 메소스, 쿠버네티스 등)에게 태스크매니저 프로세스를 실행할 컨테이너를 제공(프로비전)하도록 요청
- 유휴 태스크매니저를 종료해 계산 자원을 반환
- 태스크매니저
- 플링크의 워커(worker) 프로세스
- 일반적으로 한 플링크 클러스터는 여러 태스크매니저 가지고 있고 각 태스크매니저는 여러 슬롯을 제공
- 슬롯의 개수는 태스크매니저가 실행할 수 있는 최대 태스크 개수를 제한
- 태스크매니저를 시작할 때 태스크매니저는 자신의 모든 슬롯을 리소스매니저에 등록
- 리소스매니저에서 슬롯 제공 지시가 내려오면 태스크 매니저는 하나 이상의 슬롯을 잡매니저에 제공. 잡매니저는 실행 태스크를 이 슬롯에 할당
- 태스크가 다른 태스크매니저에 있는 태스크와 통신이 필요하면 태스크매니저를 통해 데이터를 교환
- 디스패처
- 여러 잡을 실행할 때 사용하며, 애플리케이션을 제출할 수 있는 REST 인터페이스 제공
- 사용자가 디스패처에 애플리케이션을 제출하면 디스패처는 잡매니저를 시작하고 애플리케이션을 잡매니저에게 넘김
- REST 인터페이스 덕분에 방화벽 뒤에 있는 클러스터도 HTTP를 통해 디스패처 서비스 제공 가능
- 잡 실행의 정보를 제공하는 대시보드도 실행
- 애플리케이션 제출 방식에 따라 디스패처 불필요할 수도 있음
- 그림 3-1. 애플리케이션 제출과 컴포넌트 상호작용
애플리케이션 배치
- 프레임워크 방식(Framework style)
- 플링크 애플리케이션을 하나의 JAR 파일로 패키징한 후 클라이언트를 이용해 현재 실행 중인 서비스(플링크 디스패처, 플링크 잡매니저, YARN의 리소스매니저) 중 하나로 제출
- 어떤 서비스든 클라이언트가 제출한 플링크 애플리케이션을 받아 실행하는 것 보장
- 잡매니저로 애플리케이션을 제출하면 잡매니저는 즉시 애플리케이션 실행
- 디스패처, YARN 리소스매니저로 제출하면 먼저 잡매니저를 기동하고 제출한 애플리케이션을 잡매니저로 넘김 -> 잡매니저 해당 애플리케이션 즉시 실행
- 라이브러리 방식(Library style)
- 플링크 애플리케이션을 도커(Docker) 이미지처럼 애플리케이션에 특화된 컨테이너 이미지(container image)로 만듦
- 잡매니저와 리소스매니저를 실행할 코드를 포함
- 리소스매니저와 잡매니저를 자동으로 구동하고 번들링돼 있는 잡을 제출
- 태스크매니저 컨테이너 배포는 잡과 무관한 이미지를 사용
- 이 이미지에서 시작한 컨테이너는 태스크매니저를 시작하며, 태스크매니저는 리소스매니저에 연결해 슬롯 등록
- 쿠버네티스와 같은 외부 자원 관리자가 컨테이너 이미지를 시작시키면 장애가 발생할 때 컨테이너 재시작 보장
- 프레임워크 방식은 실행 중인 서비스에 애플리케이션을 제출하는 전통적 접근 방식을 따름
- 라이브러리 방식에서는 플링크를 이용하지 않음
- 플링크 서비스를 애플리케이션과 함께 컨테이너 이미지 안에 라이브러리로 패키징
- 마이크로서비스 아키텍처는 일반적으로 이런 배치 방식 사용
태스크 실행
- 태스크매니저는 여러 태스크를 동시에 실행 가능
- 같은 연산자(데이터 병렬화), 다른 연산자(태스크 병렬화), 또는 다른 애플리케이션(잡 병렬화) 태스크가 태스크매니저의 태스크가 될 수 있음
- 태스크매니저는 데이터 처리 슬롯 개수 설정을 제공해 동시 실행 가능한 태스크의 개수 제어
- 슬롯은 연산자의 병렬 태스크 같이 스트리밍 애플리케이션의 일부분 실행
- 그림 3-2. 연산자, 태스크 처리 슬롯

- 연산자 A, C - 소스. 연산자 E - 싱크. 연산자 C, E - 병렬값이 2, 나머지 4.
- 최대 병렬 값이 4이므로, 애플리케이션 실행해 최소 4개 처리 슬롯 필요 - 각 두 개의 처리 슬롯을 가진 태스크 매니저 두 개가 있다면 요구 사항 충족 가능
- 잡매니저는 잡그래프를 실행그래프로 변환하고 네 개의 슬롯에 태스크 할당. 플링크는 병렬 값이 4인 연산자의 태스크를 각 슬롯에 할당
- 연산자를 태스크로 분할해 슬롯에 할당하면 여러 태스크를 같은 태스크매니저에 배포할 수 있는 이점 (C - 1.1, 2.1 E - 1.2, 2.2에 할당)
- 같은 프로세스 안에 있는 태스크들이 네트워크를 사용하지 않고도 데이터 교환을 효과적으로 할 수 있음
- 너무 많은 태스크를 같은 태스크매니저에 할당하면 태스크매니저에 부하가 발생해 성능이 나빠지는 역효과
- 태스크매니저는 JVM 프로세스 안에서 멀티스레드로 태스크 실행
- 스레드는 프로세스보다 더 가볍고 태스크 간 통신 비용이 싸지만 태스크 각각을 완전히 고립시킬 수 없음
- 태스크 중 하나만 오동작해도 전체 태스크매니저 프로세스가 죽고, 따라서 해당 태스크매니저에서 실행 중인 모든 태스크도 죽음
- 태스크매니저당 하나의 슬롯만 설정하면 애플리케이션을 태스크매니저 장애에서 고립시킬 수 있음
- 태스크매니저 안에서는 스레드를 이용한 병렬 방법을 사용하고, 한 호스트에 여러 태스크매니저 프로세스 배치 가능
- 플링크에 성능과 자원 고립의 상충 문제를 같이 해결할 수 있는 유연성 제공
고가용성 설정
- 애플리케이션 중 일부에 장애가 발생하더라도 애플리케이션 실행은 중단되지 않게하는 것이 중요
- 태스크매니저 실패
- 태스크매니저 중 하나가 실패하면 가용 슬롯이 떨어짐
- 이 상황에서 잡매니저는 리소스매니저에게 더 많은 슬롯을 제공하도록 요청
- 이 요청이 불가능할 때(ex. 애플리케이션이 독립형 클러스터에서 실행 중일 때) 잡매니저는 충분한 슬롯을 확보할 수 있을 때까지 애플리케이션 재실행 불가
- 애플리케이션이 재시작 전략은 잡매니저가 얼마나 자주 애를리케이션을 재시작하고 재시작 시도 동안 얼마나 오래 기다릴지 결정
- 잡매니저 실패
- 잡매니저는 완료한 체크포인트 정보와 스트리밍 애플리케이션 실행 제어 관련 메타데이터 유지
- 잡매니저가 사라지면 스트리밍 애플리케이션은 레코드 더 처리 불가
- 플링크 잡매니저는 애플리케이션의 단일 실패 지점(single point of failure)
- 잡매니저가 죽으면 다른 잡매니저로 책임과 메타데이터를 넘기는 고가용성 기능을 제공해 이 문제 해결
- 플링크의 고가용성 모드는 조율(coordination)과 합의(consensus) 기능을 분산 서비스로 제공하는 아파치 주키퍼를 기반으로 함
- 신뢰성 있는 데이터 저장소인 주키퍼를 사용해 리더 선출과 고가용성 기능 구현
- 고가용성 모드로 운영할 때 잡매니저는 잡그래프와 애플리케이션 JAR 파일처럼 필수 메타데이터를 원격의 영구 저장 시스템에 저장
- 잡매니저는 메타데이터 저장 위치 정보를 주키퍼에 저장
- 애플리케이션 실행 중 잡매니저는 각 태스크의 체크포인트 위치 정보 수집
- 모든 태스크가 자신의 상태를 원격 저장소에 저장하는 체크포인트 완료 시점이 되면 잡매니저는 태스크의 상태 정보를 원격 저장소에 저장하고 그 위치를 주키퍼에 저장
- 플링크는 잡 매니저가 실패할 때 복구에 필요한 모든 데이터를 원격 저장소에 저장하고, 주키퍼에는 저장 위치 정보를 보관
- 그림 3-3. 플링크의 고가용성 설정

- 잡매니저가 실패하면 애플리케이션에 속한 모든 태스크는 자동으로 취소되고, 실패한 잡매니저에서 모든 작업을 인계받은 새 잡매니저는 다음 절차 수행
- 원격 저장소의 잡그래프, JAR 파일, 마지막 체크포인트 위치를 주키퍼에 요청
- 애플리케이션을 계속 실행할 때 필요한 처리 슬롯을 리소스매니저로 요청
- 애플리케이션을 재시작하고 모든 태스크의 상태를 마지막 완료한 체크포인트로 재설정
- 쿠버네티스와 같은 컨테이너 환경에서 라이브러리 방식으로 애플리케이션을 실행할 때 보통 컨테이너 오케스트레이션 서비스(orchestration service)가 잡매니저나 태스크매니저 컨테이너를 자동으로 재시작
- YARN이나 메소스에서 실행할 때는 남아있는 플링크 프로세스가 잡매니저나 태스크매니저 프로세스를 재시작하는 트리거 역할을 함
- 독립형 클러스터 환경에서는 실패한 프로세스를 재시작하는 도구를 제공하지 않음
- 실패한 프로세스의 작업을 넘겨받을 수 있는 대기(standby) 잡매니저와 태스크매니저를 실행하는 것이 나을 수 있음
플링크 내부의 데이터 전송
- 태스크매니저는 전송 태스크에서 수신 태스크까지 데이터를 전송하는 역할
- 태스크매니저의 네트워크 컴포넌트는 데이터를 전송하기 전에 버퍼에 레코드를 배치(batch)로 모아서 보냄( 네트워크 버퍼 풀(network buffer pool)
- 네트워크 자원을 효율적으로 사용하고 높은 처리율을 낼 수 있는 기본적인 기술이며 네트워크나 디스크 IO에서 사용하는 버퍼링 기술과 유사
- 태스크매니저는 일대일 관계의 전용 TCP 연결을 유지해 다른 태스크매니저와 데이터를 교환
- 셔플 연결 패턴(Shuffle connection pattern)에서 각 전송 태스크는 각 수신 태스크로 데이터를 전송할 수 있어야 함
- 태스크매니저는 내부적으로 각 전송 태스크가 각 수신 태스크로 데이터를 보낼 때 사용할 수 있는 전용 네트워크 버퍼 갖고 있어야 함
- 그림 3-4. 태스크매니저 간의 데이터 전송

- 네 개의 전송 태스크는 각 수신 태스크로 데이터를 전송할 때 필요한 버퍼를 적어도 하나씩 갖고 있으며, 수신 태스크도 데이터를 받는 버퍼를 적어도 하나씩 가지고 있어야 함
- 동일 태스크매니저로 전송할 태스크 버퍼들은 동일 네트워크 연결을 통해 다중 전송(multiplex)됨
- 데이터를 셔플링하거나 브로드캐스트하는 연결일 때 각 전송 태스크는 각 수신 태스크에 대한 버퍼 하나씩 가지고 있어야 함 - 연산에 참여한 태스크 수의 제곱
- 플링크의 기본 네트워크 버퍼 설정은 중소규모 클러스터에서 사용하기 충분
- 전송 태스크와 수신 태스크가 동일 태스크매니저 프로세스에서 실행될 때 전송 태스크는 외부로 나가는 레코드를 바이트 버퍼로 직렬화한 후 버퍼가 꽉 차면 큐(queue)에 넣음
- 수신 태스크는 큐에서 버퍼를 꺼낸 후 역직렬화해 레코드 만듦
- 따라서 동일 태스크매니저에서 실행 중인 태스크는 네트워크 통신을 유발하지 않음
크레딧 기반 흐름 제어
- 버퍼링 사용은 네트워크 연결의 대역폭을 최대한 이용하는데 있어서 꼭 필요
- 스트리밍 처리 관점에서 버퍼링의 한 가지 단점은 레코드가 생성되는 즉시 전송되지 않고 버퍼에 모이면서 발생하는 지연 시간의 증가
- 플링크의 크레딧 기반 흐름 제어
- 수신 태스크가 전송 태스크에 크레딧 부여(크레딧 : 수신 태스크가 데이터를 수신하려고 예약한 네트워크 버퍼 개수)
- 수신 태스크가 전송 태스크에 크레딧 알려주면 알림을 받은 전송 태스크는 부여받은 크레딧만큼의 버퍼와 백로그 크기(backog size - 가득 차서 전송할 준비가 된 네트워크 버퍼 수)를 수신 태스크에 전송
- 수신 태스크는 예약한 버퍼로 도착한 데이터를 처리하고, 전송 태스크의 백로그 크기를 이용해 연결돼 있는 모든 전송 태스크의 다음 크레딧을 우선순위 방식으로 정함
- 수신 태스크가 데이터를 받을 수 있는 충분한 자원을 준비하자마자 데이터를 전송하므로 지연 시간 감소 가능
- L 데이터 전송이 특정 태스크에 편향(skewed) 있을 때 전송 태스크의 백로그 크기에 따라 크레딧을 부여하므로, 네트워크 자원을 균등하게 분배하는 효과적인 방식
- 플링크가 높은 처리율과 짧은 지연을 낼 수 있도록 도와주는 중요한 특징
태스크 체이닝
- 플링크는 특정 조건에서 로컬 통신의 부하를 줄여주는 태스크 체이닝(task chaining) 최적화 기법 사용
- 태스크 체이닝 요구 조건
- 두 개 이상의 연산자가 동일한 병렬값으로 설정돼 있어야 함
- 연산자들이 로컬 포워드 채널(local forward channel - 동일 프로세스에서 앞으로만 흐르는 통신 채널)로 연결돼야 함
- 그림 3-5. 태스크 체이닝 요구 조건에 따라 구성한 연산자 파이프라인

- 그림 3-6. 모든 함수를 하나로 합쳐 단일 스레드에서 실행되는 태스크에 넣고 데이터는 메서드 호출로 전달하는 태스크 체이닝
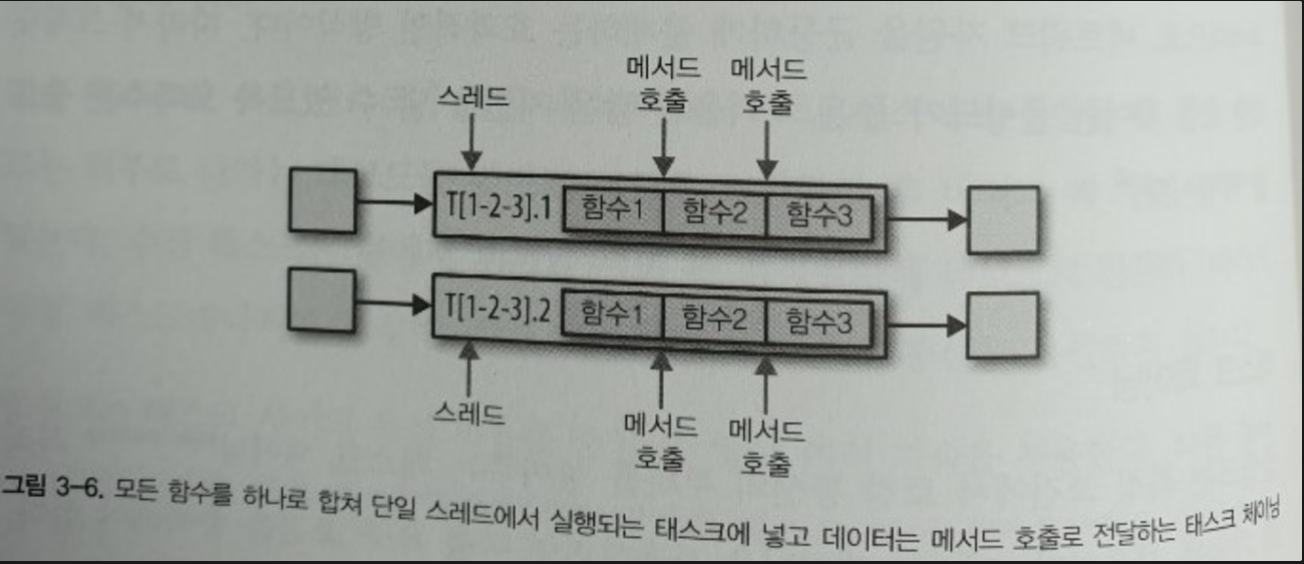
- 함수 간의 레코드 전달에 어떤 직렬화나 통신 비용이 들지 않음
- 로컬 태스크 간의 통신 비용을 극적으로 줄여줌
- 태스크 체이닝 없이 파이프라인을 실행하는 것이 옳을 때
- 많은 태스크로 구성된 긴 파이프라인을 분할하거나 태스크 체인을 여러 개로 쪼개 부하가 큰 함수를 서로 다른 슬롯에 할당
- 그림 3-7. 태스크 체이닝 없이 한 스레드에 한 태스크를 실행하여 버퍼와 직렬화를 통해 데이터 전송

- 플링크의 태스크 체이닝 기능은 기본적으로 활성화됨
이벤트 시간 처리
- 이벤트 시간 애플리케이션은 처리 시간 애플리케이션보다 추가적인 설정 필요
- 순수하게 처리시간 환경에서 동작하는 시스템 내부보다 이벤트 시간을 지원하는 스트림 처리기의 내부가 좀 더 복잡
- 플링크는 일반적인 이벤트 처리 연산에서 사용가능한 직관적이며 사용이 쉬운 여러 기본 연산자를 제공할 뿐 아니라 사용자 정의 연산자로 좀 더 복잡한 이벤트 시간 애플리케이션을 개발할 수 있도록 표현력이 풍부한 API 제공
타임스탬프
- 플링크 이벤트 시간 애플리케이션이 처리하는 모든 레코드는 타임스탬프 동반 필요
- 타임스탬프는 레코드를 특정 시점(레코드가 표현하고 있는 이벤트의 발생 시점)과 결부
- 레코드의 타임스탬프가 스트림 속도와 얼추 비슷하게 앞으로 나간다면 타임스탬프의 의미를 애플리케이션이 자유롭게 정할 수 있음)
- 이벤트 시간 모드로 데이터 스트림을 처리할 때 플링크는 레코드의 타임스탬프를 이용해 시간 기반 연산자 실행
- ex. 시간-윈도우 연산자는 타임스탬프를 이용해 윈도우에 레코드 할당
- 플링크는 타임스탬프를 16바이트의 Long값으로 변환해 레코드의 메타데이터에 첨부
- 사용자 정의 연산자에서 Long값을 마이크로초로 해석 가능
워터마크
- 이벤트 시간 애플리케이션은 레코드 타임스탬프 뿐만 아니라 워터마크도 제공해야 함
- 이벤트 시간 애플리케이션의 각 태스크는 워터마크를 사용해 현재 이벤트 시간을 얻음
- 시간 기반 연산자는 이벤트 시간을 사용해 연산을 시작하거나 스트림을 앞으로 진행시킴
- ex. 시간-윈도우 태스크는 이벤트 시간이 윈도우 경계 끝을 지날 때 윈도우에 모인 레코드들을 계산하고 그 결과를 내보냄
- 플링크는 워터마크를 Long 값의 타임스탬프를 갖고 있는 특별한 레코드를 추가해 구현
- 그림 3-8. 타임스탬프를 포함하고 있는 레코드와 워터마크가 있는 스트림

- 워터마크의 기본 속성
- 태스크의 이벤트 시간 시계(event-time clock)가 앞으로만 흘러가게 하고 역행하지 않게 함
- 레코드의 타임스퀘어와 관련 있음. T 타임스탬프를 갖고 있는 워터마크는 이후에 오는 모든 레코드의 타임스탬프가 T보다 커야 한다는 것 의미
- 레코드의 타임스탬프 순서가 바뀐 스트림을 처리하는 데 사용
- 시간 기반 연산자를 실행하는 태스크는 순서가 바뀌었을 수도 있는 레코드들을 수집하고 이벤트 시간 시계(워터마크를 수집하면서 앞으로 가는 시계)가 해당 타임스탬프와 관련된 레코드가 더 들어오지 않을 것이라 예상할 때 연산을 시작
- 태스크가 워터마크 속성을 위반하는 레코드를 받으면 이 레코드의 타임스탬프가 속해야 하는 연산은 이미 종료됐을 가능성 높음 - 연착 레코드(late records)라 함
- 플링크는 연착 레코드를 처리하는 여러 방법 제공
- 워터마크의 흥미로운 속성 중 하나는 애플리케이션 결과의 완성도와 지연을 애플리케이션이 제어할 수 있게 한다는 것
- 레코드 타임스탬프에 가까운 매우 빠듯한 워터마크는 처리 지연을 짧게 만듦 - 결과의 완성도 떨어짐 (관련 레코드가 결과에 미포함 - 연착 레코드로 생각함)
- 보수적으로 워터마크(타임스탬프에서 멀리 떨어진 워터마크)를 정하면 처리 지연 길어짐 - 결과의 완성도 높아짐
워터마크 전파와 이벤트 시간
- 플링크는 워터마크를 연산자 태스크가 받아서 내보내는 특별한 레코드로 구현
- 태스크는 내부에 타이머 서비스(timer service)를 갖고 있으며, 이 서비스는 타이머(timer)를 유지하고 워터마크가 도착할 때마다 타이머를 활성화함
- 태스크는 이 타이머 서비스에 타이머를 등록해 미래의 특정 시점에 어떤 연산 수행 가능 (ex. 윈도우 연산자)
- 태스크가 워터마크를 받으면 다음과 같은 동작 벌어짐
- 태스크는 내부 이벤트 시간 시계를 워터마크의 타임스탬프 기준으로 갱신
- 태스크의 타이머 서비스는 갱신한 이벤트 시간보다 오래된 타이머를 모두 찾음. 시간이 만료된 타이머를 등록한 태스크는 어떤 연산을 수행하거나 레코드를 내보내는 콜백 함수 호출
- 태스크는 갱신한 이벤트 시간을 워터마크에 실어서 내보냄
- 플링크는 데이터 스트림을 파티션으로 분할하고 각 파티션을 개별 연산자 태스크에 할당해 병렬로 처리
- 각 파티션은 타임스탬프가 있는 레코드와 워터마크를 흘려보내는 스트림
- 태스크 앞뒤에 어떤 연산자와 연결돼 있는지에 따라 태스크는 여러 입력 파티션에서 레코드와 워터마ㅡ를 수신하고 여러출력 파티션으로 레코드와 워터마크 전송 가능
- 태스크는 각 입력 파티션에 대해 하나의 워터마크 유지
- 입력 파티션에서 워터마크 받으면 해당 파티션의 현재 워터마크 값과 새 워터마크 값 비교해 최댓값을 새로운 워터마크로 갱신
- 태스크는 모든 입력파티션의 워터마크 중 최솟값으로 이벤트 시간 시계 값 갱신
- 이벤트 시간 시계가 앞으로 흐르면 태스크는 등록된 타이머 중 시간이 만료된 모든 타이머 활성화
- 마지막에는 연결괸 모든 출력 파티션으로 새 워터마크를 내보내 전체 하위 스트림 태스크가 새 이벤트 시간 받게 함
- 그림 3-9. 워터마크로 태스크의 이벤트 시간 갱신

- Union이나 CoFlatMap과 같은 두 개 이상의 입력 스트림을 갖고 있는 연산자의 태스크도 모든 파티션의 워터마크 중 최솟값으로 이벤트 시간 시계 계산
- 워터마크가 다른 입력 스트림에서 나오더라도 같은 파티션에서 나온 워터마크로 취급
- 결과적으로 두 입력의 레코드는 같은 이벤트 시간 시계를 기바으로 처리됨
- 두 입력 스트림에서 받은 이벤트 타임스탬프가 동기화돼 잇지 않으면 이런 동작은 문제 일으킬 수 있음
- 플링크의 워터마크 처리오 전파 알고리즘은 연산자 태스크가 생성한 레코드가 워터마크와 최대한 동기화된 타임스탬프 갖도록 보장
- 이를 위해서 모든 파티션이 지속적으로 증가하는 워터마크 제공해야 함
- 어떤 파티션의 워터마크가 더이상 아픙로 가지 않고 아무런 레코드나 워터마크 내보내지 않는다면 태스크의 이벤트 시간 시계 더 진행하지 않고 태스크 타이머도 트리거 되지 않음
- 시간 기반 연산자의 처리 지연과 상태 크기 굉장히 커질 수 있음
타임스탬프 할당과 워터마크 생성
- 보통 스트림 애플리케이션으로 스트림 데이터가 들어올 때 타임스탬프를 할당, 우터마크 생성
- 타임스탬프 결정은 애플리케이션이 하고 워터마크는 타임스탬프와 스트림의 특성에 의존하므로 애플리케이션이 명시적으로 타임스탬프를 할당하고 워터마크 생성해야 함
- 타임스탬프, 워터마크 생성 방식
- 소스에서
- SourceFunction을 통해 애플리케이션으로 스트림이 들어올 때 타임스탬프 할당, 워터마크 생성
- SourceFunction은 레코드 스트림을 내보냄. 타임스탬프는 레코드와 함께 나가고 워터마크는 특별한 레코드로 특정시점에 나감
- SourceFunction이 일시적으로 더 이상의 워터마크 내보내지 않는다면 자신을 유휴(idle)상태로 선언 가능
- 플링크는 SourceFunction의 유휴 상태 스트림 파티션을 다음 연산자의 워터마크 계산에서 제외
- 주기적인 할당자(periodic assigner)
- DataStream API : 각 레코드에서 타임스탬프를 추출하는 AssignerWithPeriodicWatermarks라 부르는 사용자 정의 함수 지원, 이 함수를 주기적으로 질의 해 현재 워터마크 알아냄
- 플링크는 추출한 타임스탬프를 각 레코드에 할당, 질의한 워터마크는 스트림에 주입
- 구두점 할당자(punctuated assigner)
- AssignerWithPunctuatedWatermarks : 각 레코드에서 타임스탬프를 추출하는 또 다른 사용자 저으이 함수. 특별한 입력 레코드에 포함된 워터마크를 추출하는데 사용 가능
- 필수는 아니지만 각 레코드에서 워터마크 추출 가능
- 연산자에 따라 레코드를 처리하고 나면 레코드의 타임 스탬프나 순서 파악이 매우 어려워질 수 있으므로 보통 소스 연산자에 가까운 곳에 사용자 정의 타임스탬프 함수 적용